Become a champion of open (data) science
Overview
Teaching: 30 min
Exercises: 60 minQuestions
How data scientist can apply open science practices in their work?
Objectives
To understand the importance to share data and code
To value code and data for what they are: the true foundations of any scientific statement.
To promote good practices for open & reproducible science
The Crisis of Confidence
As we discussed in the first part of the lesson, the crisis of confidence poses a general problem across most empirical research disciplines and is characterized by an alarmingly low rate of key findings that are reproducible (e.g., Fidler et al. 2017; Open Science Collaboration, 2015; Poldrack et al., 2017; Wager et at., 2009). A low reproducibility rate can arise when scientists do not respect the empirical cycle. Scientific research methods for experimental research are based on the hypothetico-deductive approach (see e.g., de Groot, 1969; Peirce, 1878), which is illustrated in Figure 1.
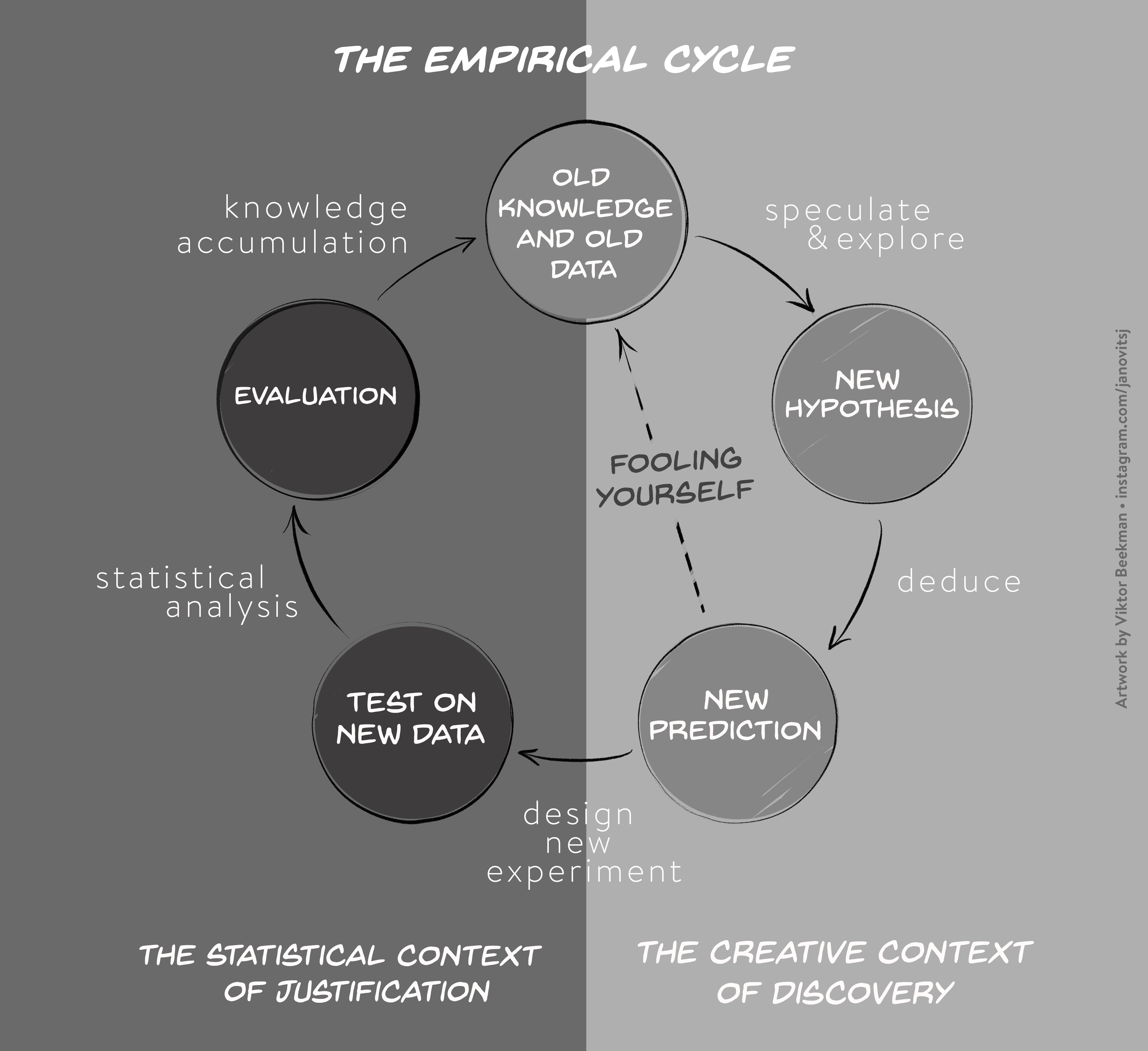
The empirical cycle suggests that scientists initially find themselves in “the creative context of discovery”, where the primary goal is to generate hypotheses and predictions based on exploration and data-dependent analyses. Subsequently, this initial stage of discovery is followed by “the statistical context of justification”. This is the stage of hypothesis-testing in which the statistical analysis must be independent of the outcome. Scientists may fool themselves whenever the results from the creative context of discovery with its data-dependent analyses are treated as if they came from the statistical context of justification. Since the selection of hypotheses now capitalizes on chance fluctuations, the corresponding findings are unlikely to replicate.
This suggests that the crisis of confidence is partly due to a blurred distinction between statistical analyses that are pre-planned and post-hoc, caused by the scientists degree of freedom in conducting the experiment, analyzing the data, and reporting the outcome. In a research environment with a high degree of freedom it is tempting to present the data exploration efforts as confirmatory (Carp, 2013). Kerr (1998, p. 204) attributed this biased reporting of favorable outcomes to an implicit effect of a hindsight bias: “After we have the results in hand and with the benefit of hindsight, it may be easy to misrecall that we had really ‘known it all along’, that what turned out to be the best post hoc explanation had also been our preferred a priori explanation.”
To overcome the crisis of confidence the research community must change the way scientists conduct their research. The alternatives to current research practices generally aim to increase transparency, openness, and reproducibility. Applied to the field of ecology, Ellison (2010, p. 2536) suggests that “repeatability and reproducibility of ecological synthesis requires full disclosure not only of hypotheses and predictions, but also of the raw data, methods used to produce derived data sets, choices made as to which data or data sets were included in, and which were excluded from, the derived data sets, and tools and techniques used to analyze the derived data sets.” To facilitate their uptake, however, it is essential that these open and reproducible research practices are concrete and practical.
Open and Reproducible Research Practices
In this section, we focus on open and reproducible research practices that researchers can implement directly into their workflow, such as data sharing, creating reproducible analyses, and the preregistration of studies.
Data Sharing
International collaboration is essential and thus the documentation, and archiving of large volume of (multinational) data and metadata is becoming increasingly important. Even though many scientists are reluctant to make their data publicly available, data sharing can increase the impact of their research. For instance, in cancer research, studies for which data were publicly available received higher citation rates compared to studies for which data were not available (Piwowar, Day, & Fridsma, 2007). This is due to the fact that other researchers can build directly on existing data, analyze them using utilize novel statistical techniques and modelling tools, and mine them from new perspectives (Carpenter et al., 2009).
Preregistration and Registered Reports
A blurred distinction between statistical analyses that are pre-planned and post-hoc causes many researchers to (unintentionally) use questionable research practices to produce significant findings (QRPs; John, Loewenstein, & Prelec, 2012). The most effective method to combat questionable research practices is preregistration, a procedure to curtail scientists’ degrees of freedom (e.g., Wagenmakers & Dutilh, 2016. When preregistering studies, scientists commit to an analysis plan in advance of data collection. By making a sharp distinction between hypothesis generating and analyzing the data, preregistration eliminates the confusion between exploratory and confirmatory research.
Over the last years, preregistration has quickly gained popularity and has established itself over several platforms and formats. Scientists can now choose to preregister their work either independently —for instance on platforms like https://asPredicted.org or the Open Science Framework (OSF)— or preregister their studies directly in a journal in the format of a Registered Report as promoted by Chris Chambers (2013). Currently about 200 journals —including Nature: Human Behaviour— accept Registered Reports either as a regular submission option or as part of a single special issue (see https://cos.io/rr/ for the full list).
Preregistration is encouraged in the transparency and openness promotion (TOP) guidelines (Nosek et al., 2015 and represents the standard for the analysis of clinical trials; for instance, in the New England Journal of Medicine —the world’s highest impact journal— the registration of Clinical Trials is a prerequisite for publication.
Reproducibility of Statistical Results
One of the core scientific values is reprodicibility. The reproducibility of experimental designs and methods allows the scientific community to determine the validity of alledged effects.
The benefit of publishing fully reporducible statistical results (including the reporting of all data preprocessing steps) is that collaborators, peer-reviewers, and independent researchers can repeat the analysis –from raw data and to the creation of relevant figures and tables– and verify the correctness of the results. Scientific articles are not free from typographical mistakes and it has been shown that the prevalence for statistical reporting errors is shockingly high. For instance, Nuijten et al. (2015) examined the prevalence of statistical reporting errors in the field of psychology and found that almost 50% or all psychological articles papers contain at least one error. These reporting errors can lead to erroneous substantive conclusions and influence, for instance, the results of meta-analyses. Most importantly, however, is that these errors are preventable. Through tools, such as git and RMarkdown, researchers can automate their statistical reporting and produce fully reproducible research papers.
The next section will explain how you can use version control and git to track your work history and collaborate with other researchers.
Three messages
If there are 3 things to communicate to others after this workshop, I think they would be:
1. Data science is a discipline that can improve your analyses
- There are concepts, theory, and tools for thinking about and working with data.
- Your study system is not unique when it comes to data, and accepting this will speed up your analyses.
This helps your science:
- Think deliberately about data: when you distinguish data questions from research questions, you’ll learn how and who to ask for help
- Save heartache: you don’t have to reinvent the wheel
- Save time: when you expect there’s a better way to do what you are doing, you’ll find the solution faster. Focus on the science.
2. Open data science tools exist
- Data science tools that enable open science are game-changing for analysis, collaboration and communication.
- Open science is “the concept of transparency at all stages of the research process, coupled with free and open access to data, code, and papers” (Hampton et al. 2015)
- For empirical researchers: transparency checklist (https://eltedecisionlab.shinyapps.io/TransparencyChecklist/)
- Repositories such as the Open Science Framework (https://osf.io/preregistration) offer preregistration templates and the tools to archive your projects
This helps your science:
- Blogpost: Seven Reasons To Work Reproducibly (written by the Center of Open Science): https://cos.io/blog/seven-reasons-work-reproducibly/
- Have confidence in your analyses from this traceable, reusable record
- Save time through automation, thinking ahead of your immediate task, reduced bookkeeping, and collaboration
- Take advantage of convenient access: working openly online is like having an extended memory _ Making your data and code publicly available can increase the impact of research.
3. Learn these tools with collaborators and community (redefined):
- Your most important collaborator is Future You.
- Community should also be beyond the colleagues in your field.
- Learn from, with, and for others.
This helps your science:
- If you learn to talk about your data, you’ll find solutions faster.
- Build confidence: these skills are transferable beyond your science.
- Be empathetic and inclusive and build a network of allies
Build and/or join a local coding community
Join existing communities locally and online, and start local chapters with friends!
Some ideas:
-
Saudi Open Science Community. This community aims to provide a place where newcomers and experienced peers interact and inspire each other to embed open science practices and values in their workflows. They are also encouraged to give feedback on policies, infrastructures and support services. It was established recently in Feb 2021.
-
RLadies. Informal but efficient communities centered on R data analysis meant to be inclusive and supportive. There is a local chapter for RLadies Saudi Arabia (Dammam) where at least one workshop is delivered each month.
-
The turing way. The Turing Way is an open source community-driven guide to reproducible, ethical, inclusive and collaborative data science. The book has a guide for reproducibility, covering version control, testing, and continuous integration.
These meetups can be for skill-sharing, showcasing how people work, or building community so you can troubleshoot together. They can be an informal “hacky hour” at a cafe or pub!
All the materials for this episode is taken directly (with minor changes) from the Introduction to Open Data Science with R workshop in the The Carpentries Incubator. At the time of completing this workshop, Marc Gallland, Tijs Bliek and Stijn Van Hoey are listed as the authors of the lesson in The Carpentries Incubator.
Key Points
Make your data and code available to others
Make your analyses reproducible
Make a sharp distincion between exploratory and confirmatory research